Introduction
This project mainly compares and contrasts between the RUST Programming Language, and the C++ Programming Language. We focus on the Cargo and Clang Compilers respectively, since they are both based on the LLVM Architecture. Thus, the low-level assembly generated by the LLVM compiler remains uniform between the two languages, and comparisons can be made.
We focus on RUST and C++ as they are both languages which are used in low-level systems programming. While the low-level LLVM compiler supports virtually any language, and currently is used for R, Python, Swift, and countless others; RUST and C++ insights give data for low-level programs, i.e. the layer on top of which all other programs are run.
Before we begin: a definition of terms
RUST
Rust is a statically-typed systems programming language known for its emphasis on memory safety, zero-cost abstractions, and high performance. It was first developed by Mozilla and released in 2010. Rust's design goals include providing a safe and concurrent alternative to C and C++, while maintaining low-level control over hardware and system resources.
This document provides an extensive overview of Rust, covering its core features, syntax, memory management, and unique aspects that set it apart from other programming languages.
Key Features
1. Memory Safety
Rust's most significant feature is its focus on memory safety. It eliminates common programming errors like null pointer dereferences and buffer overflows through its ownership system, borrow checker, and lifetime annotations. These mechanisms ensure that memory-related bugs are caught at compile time, rather than causing runtime errors.
2. Concurrency
Rust has built-in support for concurrent programming, making it easier to write safe and efficient concurrent code. The async and await keywords allow for asynchronous programming, while Rust's ownership system ensures that data races and deadlocks are prevented.
3. Zero-cost Abstractions
Rust provides high-level abstractions without sacrificing performance. The "zero-cost" philosophy means that abstractions like generics, traits, and pattern matching don't introduce runtime overhead.
4. Ownership System
Rust's ownership system is the foundation of its memory safety guarantees. It revolves around three key concepts:
Ownership: Each value in Rust has a single "owner" variable, which is responsible for cleaning up the value when it's no longer needed.
Borrowing: Multiple references (either mutable or immutable) to a value can exist simultaneously, but they must follow strict rules to prevent data races.
Lifetimes: Lifetimes annotate how long references are valid, ensuring that references don't outlive the data they point to.
5. Pattern Matching
Rust's pattern matching allows concise and expressive code for handling complex data structures. It's used extensively in control flow and destructuring.
6. Cargo
Cargo is Rust's package manager and build tool. It simplifies dependency management, building, testing, and publishing Rust projects. It also enforces conventions, making it easy to create and share libraries.
Syntax
Rust's syntax is similar to C and C++, but with some distinctive features:
Variables and Mutability
In Rust, variables are immutable by default. To make a variable mutable, you must explicitly declare it as such using the mut keyword:
let x = 42; // Immutable variable
let mut y = 42; // Mutable variable
fn add(a: i32, b: i32) -> i32 {
a + b
}
Functions
Functions in Rust are defined using the fn keyword. They can take parameters and return values:
fn main() {
let s1 = String::from("Hello"); // s1 owns the String
let s2 = s1; // Ownership transferred to s2, s1 is no longer valid
// println!("{}", s1); // This would result in an error
let s3 = String::from("World");
let len = calculate_length(&s3); // Borrowing s3 immutably
println!("Length of '{}' is {}.", s3, len);
}
fn calculate_length(s: &String) -> usize {
s.len()
}
C++
C++ is a versatile, statically-typed programming language that combines high-level abstractions with low-level system access. It was developed as an extension of the C programming language, adding object-oriented features and other modern concepts. C++ is widely used in a variety of applications, from systems programming to game development and high-performance software.
This document provides a concise overview of C++, including its key features, syntax, memory management, and unique aspects that make it a powerful and popular choice among developers.
Key Features
1. Object-Oriented Programming
C++ supports object-oriented programming (OOP) concepts such as classes, inheritance, polymorphism, and encapsulation. These features allow for modular and organized code, making it easier to manage complex projects.
2. Templates
Templates in C++ provide a powerful way to write generic code. They allow you to define functions and classes that can work with various data types without sacrificing performance. This is particularly useful for creating data structures and algorithms.
3. Standard Template Library (STL)
The STL is a collection of template classes and functions in C++. It provides a wide range of data structures (like vectors, lists, and maps) and algorithms (sorting, searching, etc.) that can be used efficiently in your programs.
4. Low-Level Memory Control
C++ offers direct memory manipulation through pointers and manual memory allocation and deallocation using new and delete. This level of control is essential for systems programming and creating custom data structures.
5. Multiple Inheritance
C++ allows a class to inherit from multiple base classes. While this feature can be powerful, it should be used carefully to prevent ambiguity and conflicts in your code.
6. Operator Overloading
C++ lets you overload operators for user-defined types, allowing you to create custom behaviors for operators like +, -, and *.
Syntax
C++ syntax shares similarities with C, but with additional features for OOP and generic programming:
Variables and Data Types
C++ provides a wide range of data types, from the fundamental types like int and double to more complex user-defined classes. Variables can be declared as follows:
int x = 42; // Integer variable
double pi = 3.14159265; // Double-precision floating-point variable
string name = "John"; // String variable
// User-defined class
class MyClass {
public:
int data;
};
MyClass obj;
obj.data = 10;
Functions
Functions in C++ are defined using the function_name keyword. They can take parameters and return values:
#include <iostream>
int add(int a, int b) {
return a + b;
}
int main() {
int result = add(5, 7);
std::cout << "The sum is: " << result << std::endl;
return 0;
}
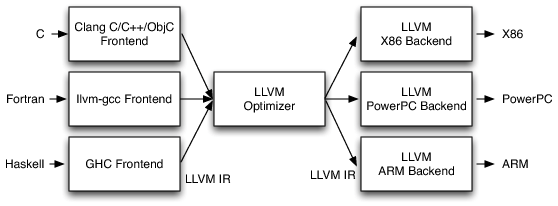
LLVM (Low-Level Virtual Machine)
LLVM, short for Low-Level Virtual Machine, is a versatile and powerful open-source compiler infrastructure. It's designed to optimize and compile high-level programming languages like Rust and C++ into efficient machine code that can run on various hardware platforms. LLVM is instrumental in modern software development, enabling performance optimization and portability.
LLVM's compilation process typically involves several stages:
- Frontend: The frontend is responsible for taking source code written in high-level programming languages like Rust and C++ and parsing it into an intermediate representation (IR). This IR is a low-level, platform-independent code that serves as the common language for further processing.
Rust/C++ Source Code -> Intermediate Representation (IR)
- Optimizer: LLVM includes a powerful optimizer that takes the IR and applies various optimization techniques to improve code performance. These optimizations may include inlining functions, eliminating dead code, and reordering instructions for better pipelining.
Intermediate Representation (IR) -> Optimized Intermediate Representation (IR)
- Backend: The backend is responsible for translating the optimized IR into machine code for a specific target architecture, like x86, ARM, or MIPS.
Optimized Intermediate Representation (IR) -> Target-Specific Machine Code
- Linker: If necessary, LLVM can invoke a linker to combine multiple object files into a single executable. The linker resolves external dependencies and generates the final binary.
Object Files -> Executable Binary
LLVM's modular design allows it to support multiple high-level programming languages, making it a preferred choice for a wide range of compilers, including Rust and Clang (for C and C++).
Here is a complete flowchart of the LLVM Compilation architecture, wherein multiple languages feed their intermediate output to LLVM, and LLVM comes out with uniform Assembly code, which further gets parsed into an executable (program)
x86 Assembly Language
x86 Assembly Language is a low-level programming language that directly corresponds to the architecture of x86-based processors. It provides a human-readable representation of machine code instructions, enabling programmers to write code that directly controls the CPU and memory. Understanding x86 Assembly is crucial for tasks like system programming, reverse engineering, and optimizing critical software components.
This document offers a basic introduction to x86 Assembly, covering its history, syntax, registers, instructions, and its role in modern computing.
History
x86 Assembly language has a long history, dating back to the original Intel 8086 processor. Over the years, it has evolved to support new features and capabilities, including 32-bit and 64-bit modes. Key developments include:
- 16-Bit x86 Assembly: Corresponding to the Intel 8086 processor.
- 32-Bit x86 Assembly: Introduced with processors like the Intel 80386, featuring extended registers and instructions.
- x86-64 Assembly (AMD64): Extending the architecture to 64 bits, providing more registers and a larger address space.
Syntax
x86 Assembly code is written using a combination of mnemonics, registers, and memory addresses. The basic structure of an x86 Assembly program is:
; Comment
section .data
; Data declarations go here
section .text
global _start
_start:
; Instructions go here
mov eax, 1 ; Syscall number for write
mov ebx, 1 ; File descriptor for stdout
mov ecx, message ; Address of the message to print
mov edx, 13 ; Message length
int 0x80 ; Call the Linux syscall
section .data
message db 'Hello, World!', 0
Comments:
Lines starting with ; are comments.
Sections:
Code is organized into sections, typically .data for data declarations and .text for executable code.
Labels:
_start is a label representing the program's entry point.
Instructions:
mov, add, sub, and other instructions perform various operations.
Registers:
x86 Assembly code makes extensive use of registers, which are fast, small storage locations inside the CPU. Common x86 registers include:
- EAX, EBX, ECX, EDX: General-purpose registers for data manipulation.
- ESP: Stack pointer for managing the stack.
- EBP: Base pointer for stack frame management.
- ESI, EDI: Index registers often used for string operations.
Instructions:
x86 Assembly instructions are mnemonics representing machine-level operations. Common instructions include:
- mov: Move data between registers or memory locations.
- add, sub, mul, div: Arithmetic operations.
- jmp, je, jl, jg: Conditional and unconditional jumps for control flow.
- push, pop: Push and pop values to/from the stack.
Role in Modern Computing:
While high-level languages like C and C++ are more commonly used for software development, x86 Assembly remains crucial for various tasks:
- System Programming: Writing operating system components and device drivers.
- Optimization: Optimizing critical sections of code for performance.
- Reverse Engineering: Analyzing and modifying compiled code.
- Embedded Systems: Developing software for resource-constrained devices.
Understanding x86 Assembly provides insight into how computers execute instructions and manage data at the lowest level, making it a valuable skill for certain domains of programming and computer science.
This is just a basic introduction to x86 Assembly language. As you delve deeper into this fascinating realm, you'll uncover the intricacies of low-level programming and its vital role in modern computing.